Türkçe
Pre-Work
It is envisaged that various protocols, services, and infrastructures currently in use will be made more useful and secure for users by various adjustments and additions to be made by working and discussion groups in accordance with joint decisions.
Four main headings to be addressed in the initial stage:
- diDb (Digital Identity Database)1
- theMe (Digital User Identity Database)
- mAPs (Memoristik Adaptation Suggestions)
- gel (Global Expanded Layer)
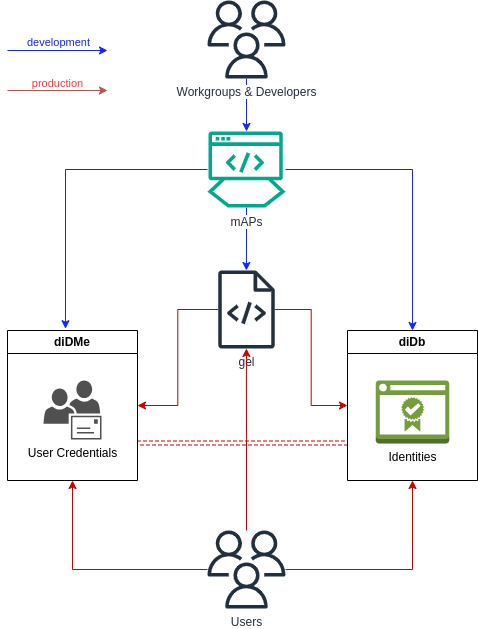
The database to be created for real individual and corporate (User) identities (theMe) will be maintained on the Blockchain, while identities for everything else (diDb) will be maintained on a Merkle Tree and communicated with each other on decentralized different servers. (The reason for preferring Blockchain for individuals is explained in the "Digital User Identity Database" section. Changes can be made according to the decision to be made by the Discussion and Working Groups.)
Digital Identity Database (diDb)
The "Decentralized Identifiers (did)" standard, also approved and supported by W3C, forms the basic idea of the diDb database to be prepared.
Due to the importance given by the Memoristik project to "minimum amount and fast data transmission," some changes can be made to the existing "did" structure, and alternative systems such as Protobuf or MessagePack may be preferred instead of text-based JSON.
According to the standards to be determined for any topic, object, or lists, a "unique" identifier will be created, and everything related to it will be linked to the number of this identifier.
A multi-layered structure is considered. Main categories of identities will be defined for identifiers on the "Core Database," and other databases will be placed under these categories through schemas2.
Categories will be divided into fixed and dynamic according to their contents. Fixed category contents will be kept in the core database, and different language category namings will be linked to each other within the core database through "aliases."
Giving examples with "Git"3,
Category (Fixed Content)
language -> 5a3cef
country -> 3b0b1d
Category (Dynamic Content)
book -> cbdedf
genre -> dd3a0b
movie -> ccf2a1
news -> 01b63a
author -> 2b4ea0
translator -> c116da
publisher -> a5d23e
bookstore -> 61e730
publishing platform -> 4a35c3
discussion/forum platform -> dc6a78
awards -> a06c1e
Categorization
Since the categories are limited, generating a 6-character identifier number is sufficient. Dynamic content categorizations can also be made by users themselves, and they can also be divided into sub/top categories when necessary. For example, Publishers and Awards can be divided by countries, in this case, when a single identifier number is used, it will automatically have the Country information.
After creating a few main categories like above, let's create some sample identities again,
book/author/movie
(book) Utsikt til paradiset -> dd129245e1dfd7312a279edcf8df17458e175359
(author) Ingvar Ambjørnsen -> 5901cd7f0faa2b647c0851f434ea266a0b9c859b
(book series and movie) Elling -> b6e8877a3d3d2484759ce72a43ba65a6be0ff3b2
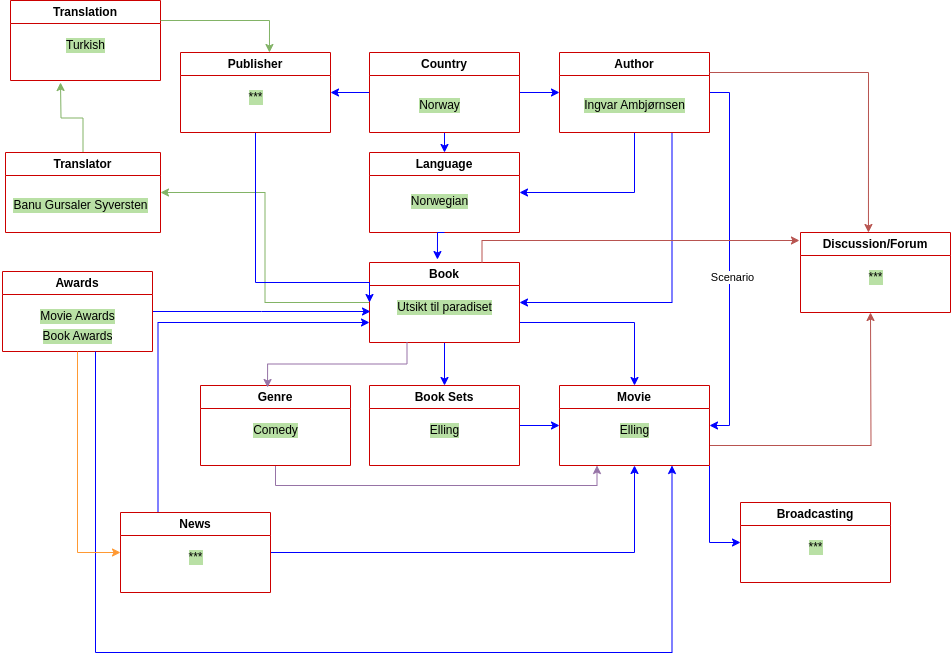
By linking these identifier numbers through schemas, we can pull out as many as we want, monitor them, contribute to them, make them contributable, and disable unwanted ones.
If we explain the same topic with some examples,
Query Examples
- All books published in any language,
- New books published by an author,
- Movies adapted from books,
- Comedy movies adapted from books,
- Media publications about a book,
- Media publications about an author,
- Award-winning films or books,
- Award-winning comedy films,
- Translated books for sale,
- Books published by a followed translator,
- Films coming to a followed publishing platform,
- Books, films published within a certain time frame,
and so on.
At this stage, users can follow any kind of person or topic, create their own lists, benefit from other lists, merge them with their own lists, and share them through the "gel" software to be prepared.
Core Database Structure
What we have described so far includes users being able to easily fetch and use ready-made data.
We can use the DNS structure as an example of this. Although we use data from ready-made servers for DNS, we can also create and use domain records on our personal computers locally. In the Memoristik project, this can be used in a way that is open to use by other users as well. We can take and use data created by people we trust.
Using the Merkle tree structure will also contribute to this; text-based and identical content data can be easily distributed to any environment. Different contents will be distributed across different servers in a distributed manner while being in communication with each other.
(SQL-based databases like "dolt" are working on such projects, and a transition to such a structure may be considered according to decisions that may come out of discussion groups in the future.)
The above example shows some basic operations, and they can be extended by users as much as they want. To give a simple example of this,
Any author can announce their book signing events, a user can create a subcategory named "Book Signing Events" and list those in their country or city, another user can incorporate this and turn it into a list including other countries, yet another user can publish a list of "Crime Writers' Book Signing Events" using these lists. Another user can check the reliability of these prepared lists and turn them into a list like "The lists published by this user are correct and reliable."
In fact, such listings can also be accessed from different platforms, but users have to search the Internet separately for each topic. In the diDB system, all of these come together, and users are left with only filtering and following the content they are interested in. Additionally, they can share their operations that they think will be useful to others through the same system.
The areas of use can expand continuously depending on what users want to do. To summarize the topic with a few more examples,
-
In the example above, the Wikipedia pages in different languages for the author have different contents. For example, the published books and awards are more visible in Norwegian and English than in Turkish. However, both lists have fixed content and could have been drawn from a single source and used collectively on pages in every language.
-
Since the sources/lists will have dynamic content, when a publisher publishes a book and notifies, and another publisher publishes its translation, it can be automatically listed on all pages on Wikipedia.
-
When a user/reader comments/rates the quality of a translation, they can be followed from both the publisher and translator lists. (Comments and ratings that platforms dislike or do not want to add will become more easily traceable from the outside.)
The example uses, development, and implementation of diDb can be tracked via Git Repo, Workgroups, and mAPs.
Digital User Identity Database (theMe)
A database is aimed to allow users to securely store their personal data and share as much as they want in a secure environment or one they trust.
Tools developed on Blockchain, with additions and changes to be made on it, seem suitable for providing this structure (for now). It is intended to be based on the Indy application being developed by the Hyperledger Foundation.
The main issues to be prioritized in the intended application are,
- Ability to create different profiles (including anonymous) within the same wallet,
- Hardware digital wallet support,
- During the transition period, the ability to add user login data from different platforms,
- Multi-user authorizations through groups,
- Sharing of information approved by third parties (Government agencies, Banks, KYC services4, Cryptocurrency Exchanges5, etc.) among different profiles,
- Distinguishing approved identities,
- Ability to sign and encrypt personal data and created content,
- Determining and tracking how signed and personalized data can be used by whom,
Digital wallets developed through Blockchain have the capacity to do some of the above, but they are being implemented in limited areas. The aim of theMe is to enable a general usage.
Working Group and Security
Digital Identity is the subject that requires the most effort. Therefore, it would be more appropriate for it to be developed by experts in an environment where "Security" is the top priority.
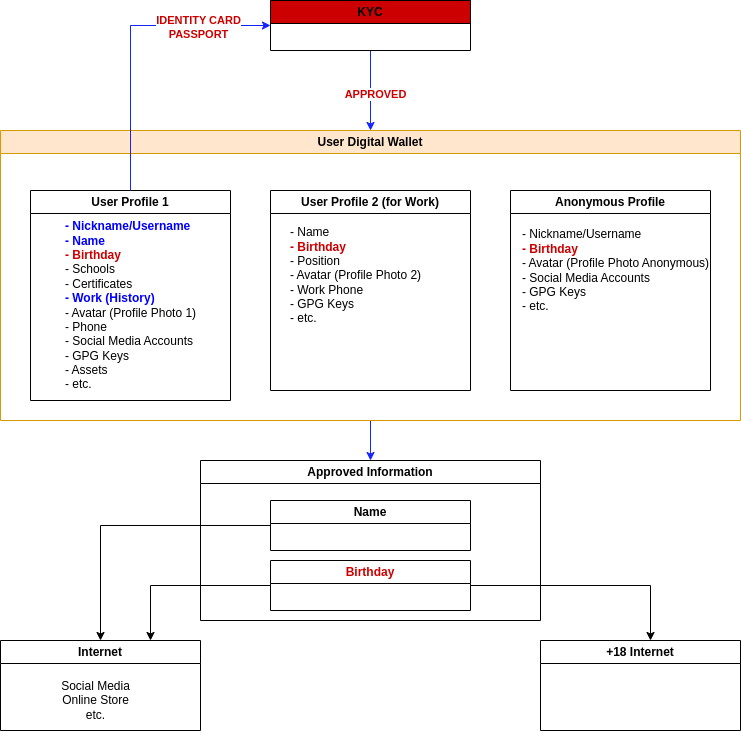
Digital Identities are used in a general way as shown above. Within the project, issues such as communication between profiles and approved/unapproved information, abstraction, KYC permissions will be clarified and put into use.
To give some examples of uses that can be expanded with extensions,
- Simplification of profile management, management of predefined information from a single point,
- When information shared with others becomes outdated and renewed, it can be updated and transmitted to the other party easily and quickly from a single point,
- All personal information (Phone, Address, Email, Social media accounts, etc.) can be published under a single "username",
- For companies, enabling quick communication with their customers, for example, definitions like "Company/Customer Representative/Order Line" can be made,
- Prevention of fraud committed on behalf of individuals or companies, real-time verification of contact information reached to a person,
The example uses, development, and implementation of theMe can be tracked via Git Repo, Workgroups, and mAPs.
Memoristik Adaptation Suggestions (mAPs)
As the days go by, (thanks to us), growing and monopolizing companies have begun to increasingly own and hide data and information generated by us. With this power they hold, they attempt to control our behaviors on the Internet.
For reasons that can be counted like these and many more, we believe that it would be much more beneficial for all of us to proceed in a way where we can make our own decisions and chart our own course. Therefore, we have created the "Adaptation Suggestions" section to ensure the development of the Memoristik project with the contributions and suggestions of its users.
Both the establishment of the technical infrastructure and the topics such as what can be done on this infrastructure will be discussed, conclusions will be reached, and after the development stage, it will be put into use.
We have started to write examples that come to mind in many areas such as Media, Social Media, Sustainability, Academic Studies, Daily Life, Shopping, Hobbies, etc. on the Git Repository. We also opened XMPP and Discord channels where we can discuss these and chat. In the near future, as communities begin to form, we plan to be active in environments such as Fediverse, Matrix, and Nostr.
The project is open to everyone's participation and will always remain so. Those who wish can participate in the topics that interest them in Discussion and Working Groups and follow the developments, contribute.
Global Expanded Layer (gel)
The most important part of the project for users is the "gel" software that will be prepared. Briefly summarizing, we can say that it is the software layer that will allow users to use theMe and diDb databases and establish the relationship between them according to the rules to be published in mAPs.
If the Protocol, which will take time to prepare and be approved and accepted as a standard by W3C, is accepted, the things the protocol is intended to do will be done through "gel" until then.
Let's try to explain with a few examples based on what we have mentioned above.
-
Profile Management (theMe)
First of all, users need a username to use this system. Records to be kept on the Hyperledger Indy-based blockchain will be saved there through "gel" and controlled. Once a username is obtained, any kind of preferred data can be added to it, and these can be shared with desired individuals.
Let's assume we have acquired a username like {@memoristik}. Let's add "name," "email," "encryption key," "logo," "document address," and "chat room" information for now.
At this stage, when {@memoristik} is written by other users through a client, "gel" can process this and send a notification to the account holder, when {@memoristik/email} is written, it can bring that person's email address.
You can easily access the website where you are reading this document from anywhere with {@memoristik/documents} or similar naming conventions.
When used in this way, the link URLs given from outside will always be protected, even if the web address changes, it will always be accessible from anywhere with a correction made by the account holder on theMe.
Similarly, when you want to join chat rooms, "gel" will offer you different options, bringing all chat room records such as xmpp, discord, matrix, etc. to the forefront. The user may have made settings themselves and may say, for example, "only show xmpp chat rooms and join there."
When a user wants to view someone else's profile through the "gel" client, all data marked as public, such as "logo," "email," "encryption key," etc., can be accessed. Personal data that is intended to remain private and only be shown to specified individuals can also be adjusted in the same way.
Examples and plans related to the use of digital wallets and profiles will be continuously added to the Git repository, and those interested can also follow from there.
As a final example, we could have linked the previous sentence as {@memoristik/repo}, and even if the repository address changes, a new address could always be accessed through this page.
Let's also take a look at what "gel" can do about scams in connection with what we have described above.
Although the infrastructure to be created will be decentralized, users can choose individuals or institutions they trust. They can use approved and reliable sources in databases prepared by them.
Any kind of message, SMS, email, etc., sent to users with the name {@memoristik} will reach the recipient after passing through signature and source control. Notifications coming from unreliable sources attempting to use this name will be blocked by "gel" before reaching the user.
Also, all emails in the email services used through "gel" will be signed by the sender, and the user will be informed for those that are not signed.
-
Content Management (diDb)
Users who have obtained a wallet from theMe and created a profile can start creating content and sharing it with other users through the "gel" software. These contents will be organized in an easily accessible manner with the help of schemas.
The important thing here is that the created content will not be stored in a single fixed location and can be published in different places such as Git Repository, IPFS, etc., in a distributable manner. Thus, for example, it will be less affected by DNS-based blockages.
The most important feature in terms of using "gel" is that users can access databases not only through servers but also through other users when necessary. Even if access to servers is restricted by official institutions, any user can access data or open data sources from another user nearby and trusted (if permitted).
Since different types of content will be kept in different places within theMe, the relationships between them will also be provided through "gel."
For example, since country and language names will generally remain fixed and change very rarely, they will be kept in the "Core Database," and content produced by individuals or institutions and listings made through content will be distributed to different places through schemas.
The only data users need in the initial stage will be the schemas created for the content they want to access (obtained from sources they trust).
Let's try to explain with a movie/series example,
First, let's create a simple schema and add data names like this: (Schemas can be named and published by the users who create them.)
Schema 1:Movie/Series Name:Country:Year:Genre
By creating this schema, we can add and publish as many movies or series as we want through "gel."
Another user can create another one using our schema:
Schema 2:@Schema 1:Director:Language:IMDB ID:IMDB Rating:Letterboxd Page:Comments:User Ratings
And another user can add,
Schema 3:@Schema 2:Platform of Release
like additions.
All other users can follow the movies or series they want by establishing connections between schemas through "gel" and query the data they want, for example:
Follow:Movie/Series Name:Genre:Platform of Release:IMDB Rating:User Ratings
forming a query like "Comedy movies released on Mubi with an IMDB rating of 8 and User Ratings of 6," and can be notified as items are added.
Additionally, with a hashtag like {#moviename} created through "gel," they can dynamically view content with a dynamic content on any HTML/Markdown page, showing only "Movie Name:Genre:Letterboxd Page."
As a final example in this section,
Schema 4(My Favorite Movies):@Schema 1:@Schema 3
a list can be prepared and published, and other users can follow and merge with their own lists.
Schema Structure and Hashtag
Schemas are written in this way for clarity. A different structure will be used when used within "gel," and the appropriate format will be added and excluded data according to the content.
The use of hashtags is also given as an example. Adjustments will be made according to the format of the content to ensure easy access.
Platform-Based Shared Lists
One of the features to be added to "gel" software will be its ability to link shared content on different platforms.
For example, when a link to a music piece or list available on both YouTube and Spotify is shared among users, users will be able to listen from their preferred platform with the help of "gel."
A usage like {@bethhart:#badwomanblues} will be shown to the user by "gel" with the link of the preferred platform,
youtube -> qiRiPtg9EFk
spotify -> 0rOzFVPfQiJShjum8zpfu9
will be resolved in the background, and the user will be directed to the preferred application.
ID Merging
For "gel" to be able to do this, Artificial Intelligence software can be used before the contents of the diDb database are created, the same parts can be found and matched (primarily from official accounts if available) and added to the database.
Also, the data sets Metabrainz is starting to create and Acoustid data can be used by communicating with them.
Since official accounts can also be defined on theMe and diDb, matching will be easier. For example, the Youtube and Spotify profiles of the {@bethhart} account may have been defined by herself.
Official Account Contents
One of the conveniences provided by "gel" will be to minimize the need to repeat content on different platforms.
For example, when all kinds of technical information about a newly released product are added to the database by the manufacturer, when another content related to the product is desired to be produced, it can be directly fetched from there.
When an online shopping site wants to sell a Fujifilm XT-2 and show its information to its customers, it will be sufficient to add a content like {@fujifilm:camera:xt-2}. Customers can ensure that there is no incorrectly entered information.
Similarly, on the user side, by using the query determined by themselves when they encounter {@fujifilm:camera:xt-2} content, they can quickly access any kind of data with "Product rating," "Places sold," "Compatible hardware," "User comments," etc.
Samples
We have tried to explain the Memoristik project, which we have planned, pre-worked, and plan to implement in the near future, with some examples. However, both to avoid extending the description too much and to create a place where everyone can discuss and discuss, most of our examples will be written on the Git Repository.
Some of them can also be found on the "Sample Usages" and "Blog" pages for a better understanding of the project.
-
Although the direct translation of the word "Identifier" is "Tanımlayıcı", it will be used as "Kimlik" here. ↩
-
How schemas can be structured and used is explained under the "gel" heading. ↩
-
"Git" seems almost ready for use with some changes and additions, and if a decision is made for a different Merkle Tree for the project database, the hashing infrastructure can be used. The main purpose of giving an identity number is that it will be easily decipherable by everyone, so solutions like SHA1/SHA512 can be used directly. The important thing is to prevent collisions. Additionally, open-source Git Repositories can be adapted to the project with some changes. ↩
-
"Know Your Customer (KYC)" system ↩
-
Cryptocurrency exchanges require identity, photo, etc., information to be given to be able to trade. Therefore, they can also be given authorization. However, this issue is intended to be clarified in Discussion Groups. ↩